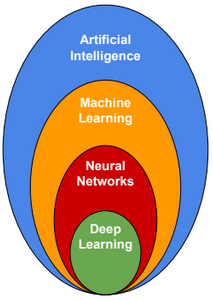
Without any doubt Machine Learning / Artificial Intelligence will drastically change the world during the next decade. Deep Learning algorithms are reaching unprecedentedly high level of accuracy, but they are slow to train. For this reason Big companies are working on a design of new chips optimized to run Deep Learning algorithms.
Machine Learning Research Scientists

Below the list of some known Machine Learning research scientists:
|
Geoffrey Hinton |
Former University of Toronto professor. The godfather of neural network research. |
|
Andrew Ng |
Adjunct professor at Stanford University. Founder of Google Brain project. |
|
Yann LeCun |
Director of AI Research at Facebook. Founding father of convolutional neural network. |
|
Yoshua Bengio |
Full professor at Universit� de Montr�al. One of the founding fathers of deep learning. |
Machine Learning Platforms
Microsoft Azure ML: https://studio.azureml.net/
Google ML: https://cloud.google.com/ml/
Amazon ML: http://aws.amazon.com/machine-learning/
Machine Learning Frameworks
Caffe2(Facebook), PyTorch(Facebook), Tensorflow(Google), Paddle(Baidu), CNTK(Microsoft), MXNet(Amazon).
High-Performance Hardware for Machine Learning
GPGPU Architecture
General-purpose computing on graphics processing units is the use of a graphics processing unit (GPU) to perform computations in applications traditionally handled by the central processing unit (CPU). There are GPU programming frameworks that allow the use of GPUs for general purpose tasks. The widely used frameworks are Cuda and OpenCL. Cuda is supported only on NVIDIA GPUs. OpenCL is open standard, it’s supported on most recent Intel and AMD GPUs.
FPGA Architecture
FPFAs are hardware implementations of algorithms, and hardware is always faster than software. A use of a multiple-FPGA parallel computing architecture can dramatically improve computing performance.
Tensor Processing Unit
TPUs are application-specific integrated circuits developed specifically for machine learning. They are designed explicitly for a higher volume of reduced precision computation (as little as 8-bit precision).
https://en.wikipedia.org/wiki/Tensor_processing_unit.