Microsoft Cognitive Toolkit, is a deep learning framework developed by Microsoft Research.
Multilayer Perceptron Network
Perceptron means Binary Classifier. It learns whether an input belongs to some specific class or not.
import cntk as C
import matplotlib.pyplot as plt
import numpy as np
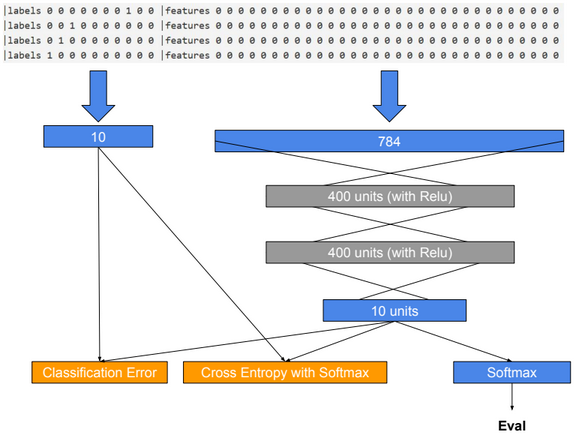
input_dim = 784
num_output_classes = 10
input = C.input_variable(input_dim)
label = C.input_variable(num_output_classes)
input_s = input/255
with C.layers.default_options(init = C.layers.glorot_uniform(), activation = C.ops.relu):
num_hidden_layers = 2
hidden_layers_dim = 200
h = input_s
for _ in range(num_hidden_layers):
h = C.layers.Dense(hidden_layers_dim)(h)
z = C.layers.Dense(num_output_classes, activation = None)(h) #no activation function in output layer
loss = C.cross_entropy_with_softmax(z, label)
label_error = C.classification_error(z, label)
learning_rate = 0.2
lr_schedule = C.learning_rate_schedule(learning_rate, C.UnitType.minibatch)
learner = C.sgd(z.parameters, lr_schedule)
trainer = C.Trainer(z, (loss, label_error), [learner])
minibatch_size = 64
total_num_examples = 60000
num_epochs = 5
num_minibatches = (total_num_examples * num_epochs) / minibatch_size
labelStream = C.io.StreamDef(field=’labels’, shape=num_output_classes, is_sparse=False)
featureStream = C.io.StreamDef(field=’features’, shape=input_dim, is_sparse=False)
deserailizer = C.io.CTFDeserializer(‘data/MNIST/Train-28x28_cntk_text.txt’
, C.io.StreamDefs(labels = labelStream, features = featureStream))
reader_train = C.io.MinibatchSource(deserailizer, randomize = True, max_sweeps = C.io.INFINITELY_REPEAT)
input_map = { label : reader_train.streams.labels, input : reader_train.streams.features }
plotdata = {“batch_number”:[], “loss”:[], “error”:[]}
for i in range(0, int(num_minibatches)):
data = reader_train.next_minibatch(minibatch_size, input_map = input_map)
trainer.train_minibatch(data)
if i % 500 == 0:
training_loss = trainer.previous_minibatch_loss_average
eval_error = trainer.previous_minibatch_evaluation_average
print (“Minibatch: {0}, Loss: {1:.4f}, Error: {2:.2f}%”.format(i, training_loss, eval_error*100))
if not (training_loss == “NA” or eval_error ==”NA”):
plotdata[“batch_number”].append(i)
plotdata[“loss”].append(training_loss)
plotdata[“error”].append(eval_error)
plt.figure(1)
plt.subplot(211)
plt.plot(plotdata[“batch_number”], plotdata[“loss”], ‘b–‘)
plt.xlabel(‘Minibatch number’)
plt.ylabel(‘Loss’)
plt.title(‘Minibatch run vs. Training loss’)
plt.show()
plt.subplot(212)
plt.plot(plotdata[“batch_number”], plotdata[“error”], ‘r–‘)
plt.xlabel(‘Minibatch number’)
plt.ylabel(‘Label Prediction Error’)
plt.title(‘Minibatch run vs. Label Prediction Error’)
plt.show()
deserailizer = C.io.CTFDeserializer(‘data/MNIST/Test-28x28_cntk_text.txt’
, C.io.StreamDefs(labels = labelStream, features = featureStream))
reader_test = C.io.MinibatchSource(deserailizer, randomize = True, max_sweeps = C.io.INFINITELY_REPEAT)
test_input_map = {
label : reader_test.streams.labels,
input : reader_test.streams.features,
}
# Test data for trained model
test_minibatch_size = 512
num_samples = 10000
num_minibatches_to_test = num_samples // test_minibatch_size
test_result = 0.0
for i in range(num_minibatches_to_test):
data = reader_test.next_minibatch(test_minibatch_size, input_map = test_input_map)
eval_error = trainer.test_minibatch(data)
test_result = test_result + eval_error
print(“Average test error: {0:.2f}%”.format(test_result*100 / num_minibatches_to_test))
# Eval data for trained model
out = C.softmax(z)
deserailizer = C.io.CTFDeserializer(‘data/MNIST/Test-28x28_cntk_text.txt’
, C.io.StreamDefs(labels = labelStream, features = featureStream))
reader_eval = C.io.MinibatchSource(deserailizer, randomize = False, max_sweeps = C.io.INFINITELY_REPEAT)
eval_minibatch_size = 25
eval_input_map = {input: reader_eval.streams.features}
data = reader_eval.next_minibatch(eval_minibatch_size, input_map = test_input_map)
img_label = data[label].asarray()
img_data = data[input].asarray()
predicted_label_prob = [out.eval(img_data[i]) for i in range(len(img_data))]
pred = [np.argmax(predicted_label_prob[i]) for i in range(len(predicted_label_prob))]
gtlabel = [np.argmax(img_label[i]) for i in range(len(img_label))]
print(“Label :”, gtlabel[:25])
print(“Predicted:”, pred)
Convolutional Neural Network
import cntk as C
import matplotlib.pyplot as plt
import numpy as np
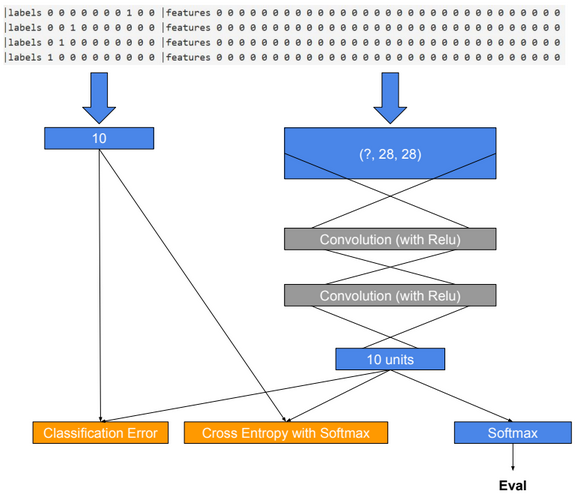
input_dim_model = (1, 28, 28)
input_dim = 28*28
num_output_classes = 10
input = C.input_variable(input_dim_model)
label = C.input_variable(num_output_classes)
input_s = input/255
with C.layers.default_options(init=C.glorot_uniform(), activation=C.relu):
h = input_s
h = C.layers.Convolution2D(filter_shape=(5,5), num_filters=8, strides=(2,2), pad=True, name=’first_conv’)(h)
h = C.layers.Convolution2D(filter_shape=(5,5), num_filters=16, strides=(2,2), pad=True, name=’second_conv’)(h)
z = C.layers.Dense(num_output_classes, activation=None, name=’classify’)(h)
loss = C.cross_entropy_with_softmax(z, label)
label_error = C.classification_error(z, label)
learning_rate = 0.2
lr_schedule = C.learning_rate_schedule(learning_rate, C.UnitType.minibatch)
learner = C.sgd(z.parameters, lr_schedule)
trainer = C.Trainer(z, (loss, label_error), [learner])
minibatch_size = 64
total_num_examples = 60000
num_epochs = 10
num_minibatches = (total_num_examples * num_epochs) / minibatch_size
labelStream = C.io.StreamDef(field=’labels’, shape=num_output_classes, is_sparse=False)
featureStream = C.io.StreamDef(field=’features’, shape=input_dim, is_sparse=False)
deserailizer = C.io.CTFDeserializer(‘data/MNIST/Train-28x28_cntk_text.txt’
, C.io.StreamDefs(labels = labelStream, features = featureStream))
reader_train = C.io.MinibatchSource(deserailizer, randomize = True, max_sweeps = C.io.INFINITELY_REPEAT)
input_map = { label : reader_train.streams.labels, input : reader_train.streams.features }
# Number of parameters in the network
C.logging.log_number_of_parameters(z)
plotdata = {“batch_number”:[], “loss”:[], “error”:[]}
for i in range(0, int(num_minibatches)):
data = reader_train.next_minibatch(minibatch_size, input_map = input_map)
trainer.train_minibatch(data)
if i % 500 == 0:
training_loss = trainer.previous_minibatch_loss_average
eval_error = trainer.previous_minibatch_evaluation_average
print (“Minibatch: {0}, Loss: {1:.4f}, Error: {2:.2f}%”.format(i, training_loss, eval_error*100))
if not (training_loss == “NA” or eval_error ==”NA”):
plotdata[“batch_number”].append(i)
plotdata[“loss”].append(training_loss)
plotdata[“error”].append(eval_error)
plt.figure(1)
plt.subplot(211)
plt.plot(plotdata[“batch_number”], plotdata[“loss”], ‘b–‘)
plt.xlabel(‘Minibatch number’)
plt.ylabel(‘Loss’)
plt.title(‘Minibatch run vs. Training loss’)
plt.show()
plt.subplot(212)
plt.plot(plotdata[“batch_number”], plotdata[“error”], ‘r–‘)
plt.xlabel(‘Minibatch number’)
plt.ylabel(‘Label Prediction Error’)
plt.title(‘Minibatch run vs. Label Prediction Error’)
plt.show()
deserailizer = C.io.CTFDeserializer(‘data/MNIST/Test-28x28_cntk_text.txt’
, C.io.StreamDefs(labels = labelStream, features = featureStream))
reader_test = C.io.MinibatchSource(deserailizer, randomize = True, max_sweeps = C.io.INFINITELY_REPEAT)
test_input_map = {
label : reader_test.streams.labels,
input : reader_test.streams.features,
}
# Test data for trained model
test_minibatch_size = 512
num_samples = 10000
num_minibatches_to_test = num_samples // test_minibatch_size
test_result = 0.0
for i in range(num_minibatches_to_test):
data = reader_test.next_minibatch(test_minibatch_size, input_map = test_input_map)
eval_error = trainer.test_minibatch(data)
test_result = test_result + eval_error
print(“Average test error: {0:.2f}%”.format(test_result*100 / num_minibatches_to_test))
# Eval data for trained model
out = C.softmax(z)
deserailizer = C.io.CTFDeserializer(‘data/MNIST/Test-28x28_cntk_text.txt’
, C.io.StreamDefs(labels = labelStream, features = featureStream))
reader_eval = C.io.MinibatchSource(deserailizer, randomize = False, max_sweeps = C.io.INFINITELY_REPEAT)
eval_minibatch_size = 25
eval_input_map = {input: reader_eval.streams.features}
data = reader_eval.next_minibatch(eval_minibatch_size, input_map = test_input_map)
img_label = data[label].asarray()
img_data = data[input].asarray()
img_data = np.reshape(img_data, (eval_minibatch_size, 1, 28, 28))
predicted_label_prob = [out.eval(img_data[i]) for i in range(len(img_data))]
pred = [np.argmax(predicted_label_prob[i]) for i in range(len(predicted_label_prob))]
gtlabel = [np.argmax(img_label[i]) for i in range(len(img_label))]
print(“Label :”, gtlabel[:25])
print(“Predicted:”, pred)
LSTM
import cntk as C
import numpy as np
import math
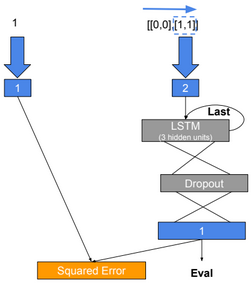
x = C.sequence.input_variable(2)
l = C.input_variable(1)
nbr_hidden_units = 3
with C.layers.default_options(initial_state = 0.1):
m = C.layers.Recurrence(C.layers.LSTM(nbr_hidden_units))(x)
m = C.sequence.last(m)
#m = C.layers.Dropout(0.2)(m)
z = C.layers.Dense(1)(m)
learning_rate = 0.1
lr_schedule = C.learning_rate_schedule(learning_rate, C.UnitType.minibatch)
loss = C.squared_error(z, l)
error = C.squared_error(z, l)
learner = C.sgd(z.parameters, lr = lr_schedule)
trainer = C.Trainer(z, (loss, error), [learner])
for i in range(0, 5):
trainer.train_minibatch({
x: [[[0,0],[1,1]],[[1,1]],[[2,2]]],
l: [[0],[1],[2]]
})
z.eval({x: [[[0,0],[1,1]]]})
z.parameters